Robot Foundation Models explained
The intelligence behind humanoid robots doesn’t come from a single AI system. It comes from a layered stack of specialized foundation models, each solving a different part of the problem. This guide explains every category – what they do, how they differ, and who is building them. Humanoid Robot foundation models, or models targeted towards Embodied AI, are also referred to as Large Behavior Models (LBM), Robot Foundation Models(RFM), Generalist Robot Policies (GRP), or Embodied Foundation Models (EFM). Here are the most popular model variants. You can click them for an in-depth explanation:
What Are World Models in Robotics?
A World Model is the robot’s internal simulation of reality. Rather than reacting purely to sensor input, a robot with a World Model can predict what will happen next – imagining the consequences of actions before executing them.
World Models emerged from deep learning research — where models like DreamerV3 and RSSM showed that agents could learn to plan inside a learned latent space. In humanoid robotics, this concept has become central to how robots handle novel environments without needing endless real-world training data.
New! 2026 Humanoid
Robot Market Report
198 pages of exclusive insight from global robotics experts — uncover funding trends, technology challenges, leading manufacturers, supply chain shifts, and surveys and forecasts on future humanoid applications.

now Google DeepMind
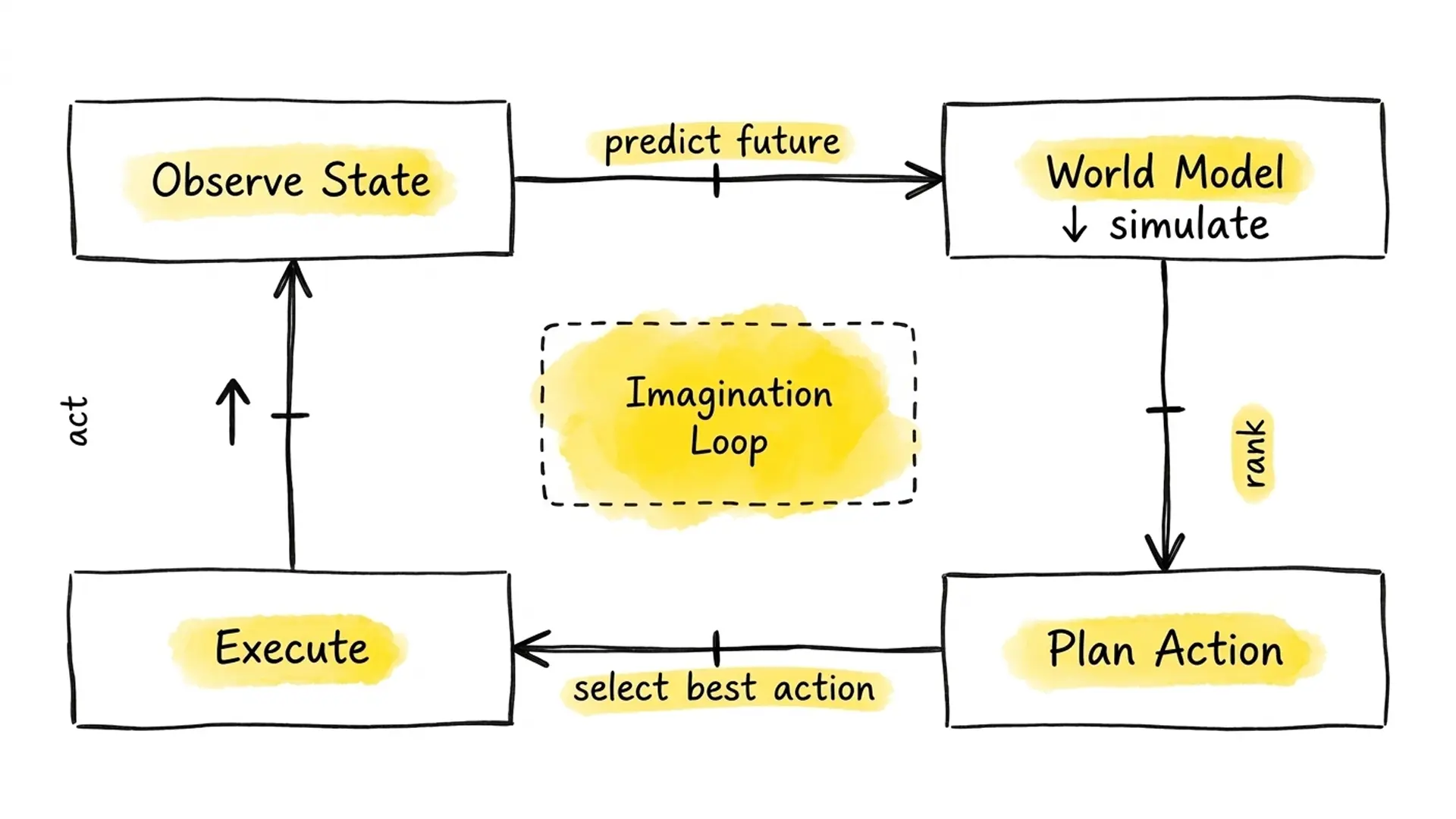
Fig. 01 – The World Model imagination loop. The robot encodes state, simulates possible futures in latent space, selects an optimal action, and executes – continuously refining its internal model from real outcomes.
A World Model typically does three things: it encodes the current state of the environment, predicts the next state given a proposed action, and estimates uncertainty. Together, these capabilities allow a robot to mentally rehearse a task before committing to physical motion.
The distinction from a VLA model matters: a World Model focuses on prediction and planning, while a VLA maps perception directly to action. Researchers increasingly combine the two – World Models provide the planning backbone while VLAs handle the moment-to-moment policy execution.
Key research directions include video prediction models like Genie 2 and UniSim, physical world simulators, and latent dynamics models trained on large-scale robot teleoperation datasets.
Vision-Language-Action: The Robot Brain
VLA stands for Vision-Language-Action. These models take what a robot sees and what an operator tells it, and turn that directly into movement – the closest thing yet to a general-purpose robot brain.
VLA models are end-to-end: they consume visual input (camera frames), language input (a task instruction like “pick up the red cup”), and output motor commands or action tokens. This marks a radical departure from modular pipelines, where separate subsystems handled perception, planning, and control independently.
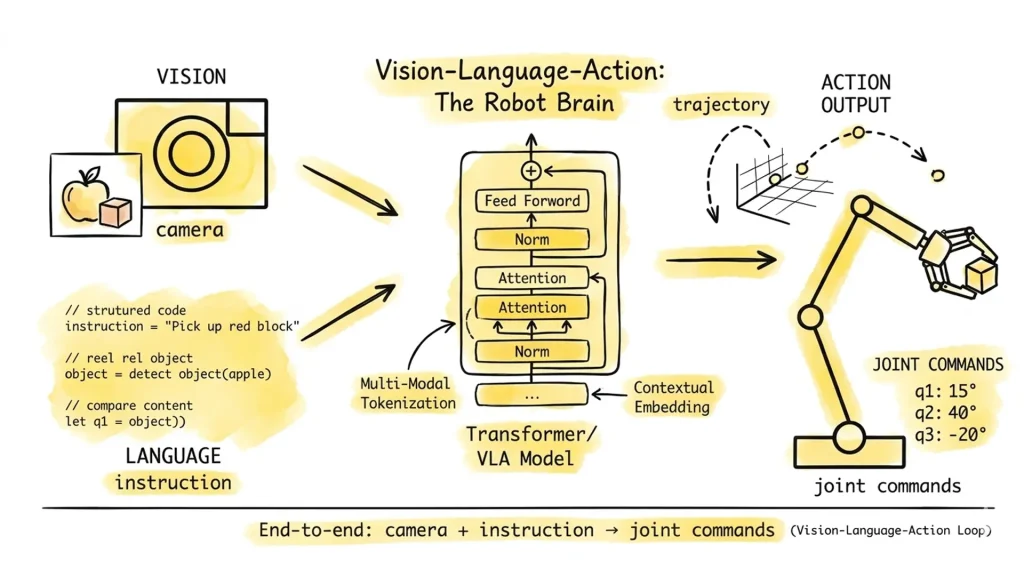
Fig. 02 – VLA end-to-end architecture. Visual tokens and language tokens are fused inside a large transformer. The model directly outputs action tokens that drive robot joints — no separate perception or planning modules.
The architecture typically builds on a Vision-Language Model (VLM) – such as PaLM-E, Llama-based variants, or custom transformer architectures – with an action head or diffusion-based action decoder attached. Early VLAs drew on models like PaLI and LLaVA for their vision-language backbone, but leading 2025–2026 systems have largely moved to purpose-built or heavily modified architectures optimised for low-latency action generation.. Researchers train the model on large datasets of robot demonstrations, often combining these with internet-scale video and language data to improve generalization.
Leading examples include Google’s RT-2, π0 from Physical Intelligence, OpenVLA, and Octo. Each takes a different approach to tokenizing actions, handling multimodal context, and generalizing across robot bodies.
One of the core unsolved challenges is the embodiment gap – a model trained on one robot hardware often fails on another. This drives active research into unified action representations and cross-embodiment training datasets.
Reward Models: Teaching Robots What “Good” Looks Like
Reward Models define what success looks like. Instead of hand-coding rules for every situation, a Reward Model learns to score robot behavior – telling the training pipeline which actions are good, bad, or somewhere in between.
In reinforcement learning, an agent learns by maximizing reward. The traditional approach was to engineer reward functions manually – notoriously difficult in contact-rich manipulation and locomotion tasks. Reward Models replace this with a learned evaluator, often trained on human preference data or demonstrations.
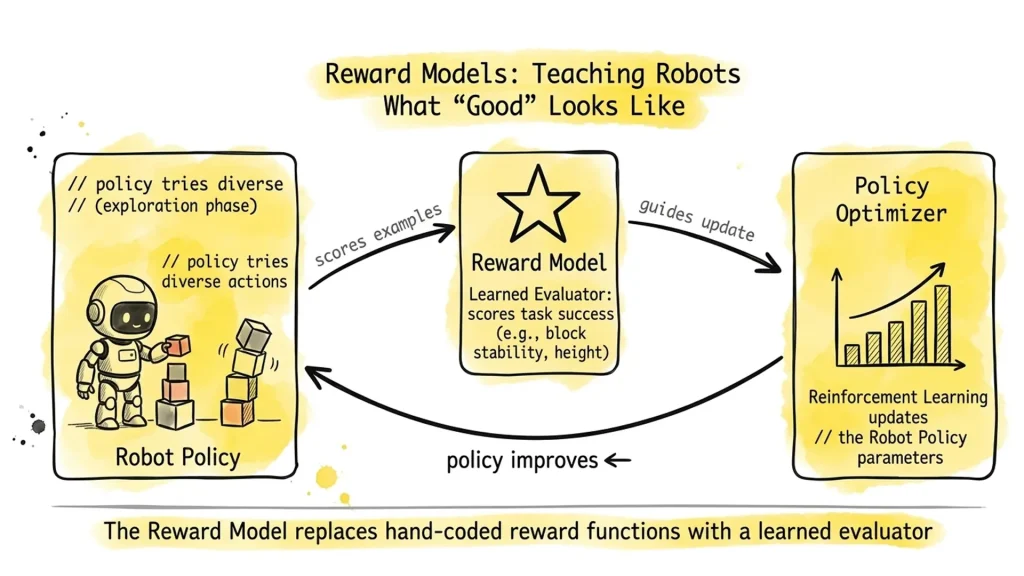
Fig. 03 – The Reward Model training loop. The robot attempts a task; the Reward Model scores the behavior; the Policy Optimizer updates the policy accordingly. This loop runs thousands of times – without human intervention after the Reward Model is trained.
In humanoid robotics, Reward Models serve two main purposes. First, as training-time supervisors: the robot generates candidate behaviors, and the Reward Model scores them to drive policy improvement. Second, as online critics: deployed alongside a policy to filter or rerank actions in real time.
Recent advances explore using large vision-language models as zero-shot reward functions — prompting a model to evaluate whether a video clip shows a task being successfully completed. This dramatically reduces annotation burden and enables reward generalization to new tasks.
The connection to RLHF (Reinforcement Learning from Human Feedback) is direct — the same techniques that aligned LLMs like GPT-4 now drive robot policy training as well.
Diffusion Policies: Generating Actions Like Images
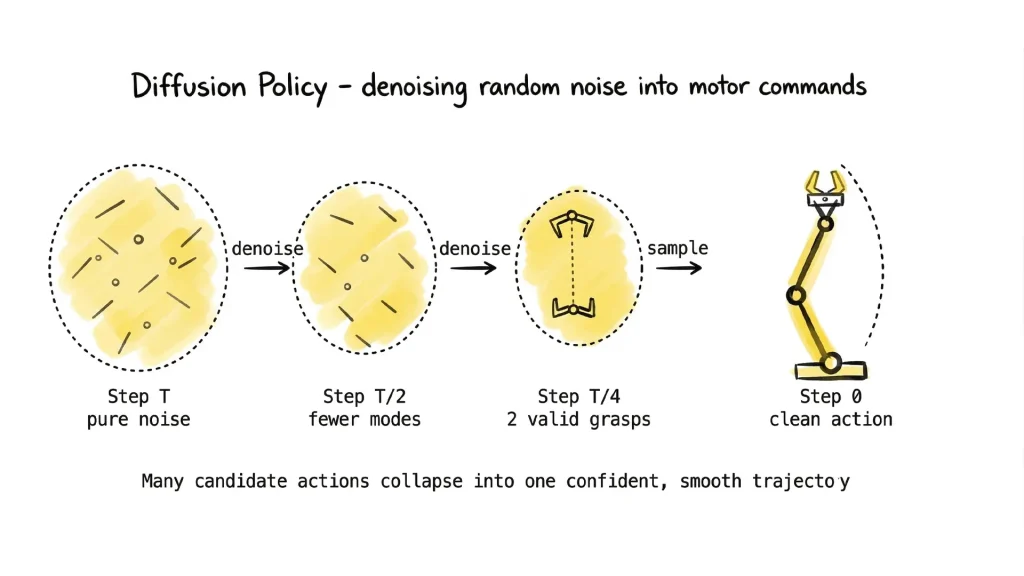
Diffusion Policies apply the same denoising process used in image generation models — like Stable Diffusion — to the problem of robot action generation. Instead of generating pixels, a diffusion policy generates motor commands.
The key insight is that complex, multi-modal action distributions are difficult to represent with a standard regression head. When a robot reaches for an object, there are often many valid ways to grasp it — a single deterministic output forces the model to average across them, producing mediocre results. A diffusion process handles this naturally, sampling from a distribution of plausible actions and producing crisp, confident motion.
Open vs. Closed: A Critical Divide Across All Foundation Models
Open Weights models are foundation models where the trained parameters are publicly released. For the humanoid robotics field, this is a critical distinction – it enables labs, startups, and independent researchers to build on state-of-the-art models without starting from scratch.
Open Weights is not a model type – it’s a property that applies across all the categories above. Any foundation model (World Model, VLA, Reward Model, or Omni-Body policy) can be released as open weights or kept closed. The distinction matters enormously for how the field develops.
Open weights models – such as Octo, OpenVLA, and RoboFlamingo – release their trained parameters publicly, allowing labs, startups, and independent researchers to download, fine-tune, and deploy without starting from scratch. Closed models, such as π0 and RT-2, are accessible only via API or controlled deployment.
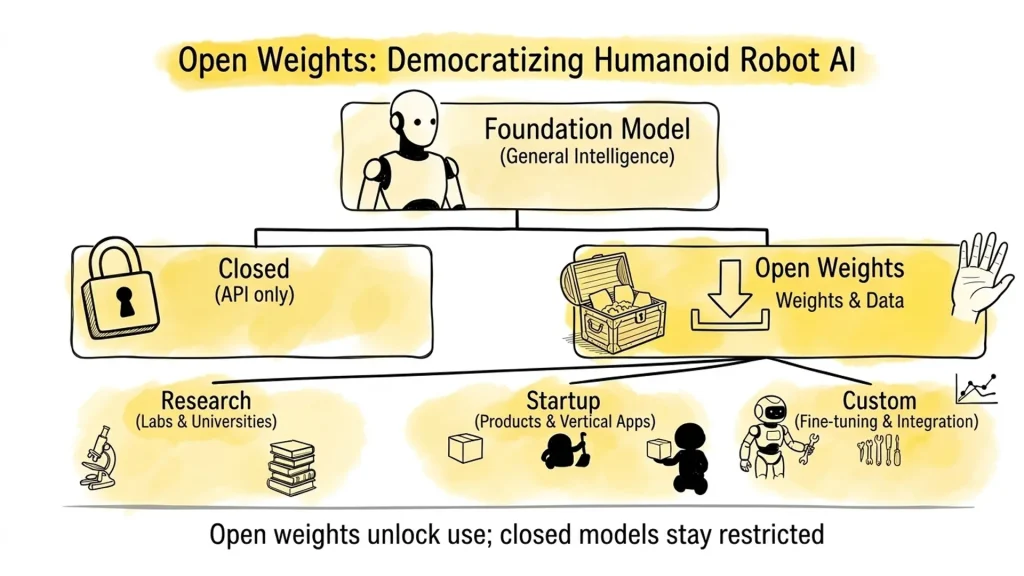
Fig. 04 – The Open vs. Closed split. Closed models are accessible only via API – a black box. Open weights can be downloaded, inspected, fine-tuned, and deployed across research, commercial, and custom use cases.
Open weights should not be confused with open source. A model can release weights without publishing training code, datasets, or full methodology. The distinction matters for researchers who want to replicate results or understand model behavior at a deeper level.
Key considerations when adopting open weights models include: license terms (commercial use restrictions are common), hardware requirements (many large VLAs need multi-GPU setups), and whether fine-tuning data pipelines are publicly available alongside the weights.
For humanoid.guide, the Open Weights filter surfaces models where you can actually download and run the parameters – an important signal for labs making build-vs-buy decisions in robot AI infrastructure.
Omni-Body Models: One Policy Across Every Robot Form
Omni-Body models are trained to work across multiple robot embodiments – wheeled robots, quadrupeds, arms, and full humanoids – without a separate model for each body type.
The challenge of embodiment is one of the deepest in robotics AI. A policy trained on a 7-DoF arm fails on a 6-DoF arm. A locomotion controller trained on a specific quadruped fails on a different leg geometry. Every time the hardware changes, the model breaks.
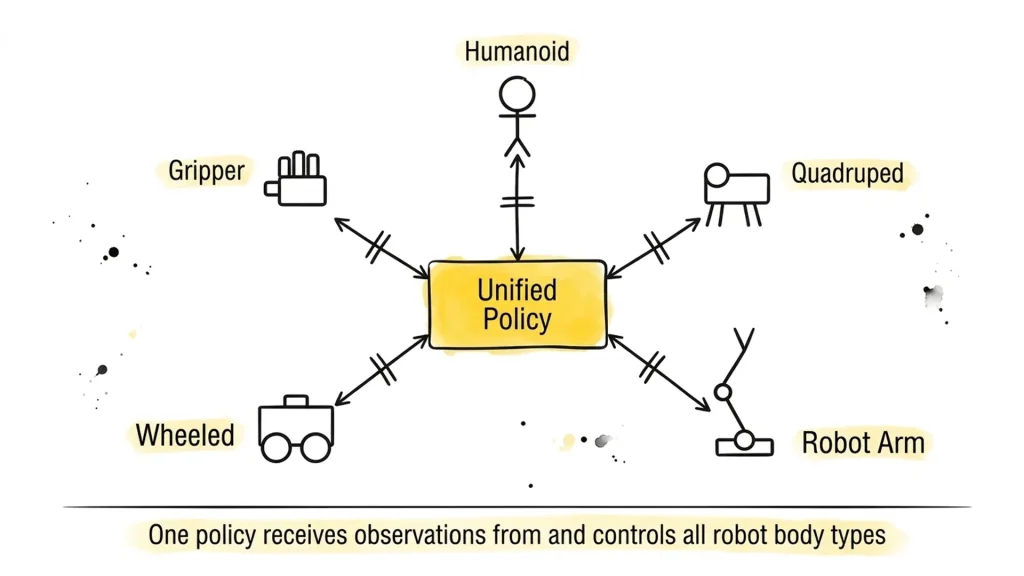
Fig. 05 – Omni-Body radial architecture. A single unified policy receives observations from and outputs actions for five different robot morphologies – without retraining or fine-tuning for each new body.
Omni-Body research addresses this by learning embodiment-agnostic representations – internal features that capture task semantics and physical dynamics without being tied to specific joint configurations or sensor layouts. Techniques include morphology-conditional architectures, graph neural networks over kinematic trees, and cross-embodiment datasets like Open X-Embodiment (OXE).
For humanoid robotics specifically, Omni-Body models matter because the field still lacks hardware standardization. A company betting on a single robot platform today risks obsolescence. A model that generalizes across bodies is a more durable infrastructure investment.
Google DeepMind’s cross-embodiment policies and Physical Intelligence’s π0 architecture both push toward this goal – training on diverse robot data to improve generalization even within a specific target embodiment.
Humanoid-Only Models: Built for the Human Form Factor
While many robot foundation models aim for broad generalization, researchers design – or specifically evaluate – Humanoid-Only models for full-body humanoid robots with bipedal dynamics, dexterous hands, and whole-body coordination.
Humanoids are mechanically among the most complex robots ever built. With 30–50 degrees of freedom, contact-rich whole-body dynamics, and the need to handle fragile objects in cluttered spaces, they present challenges that general robot policies often fail to address.
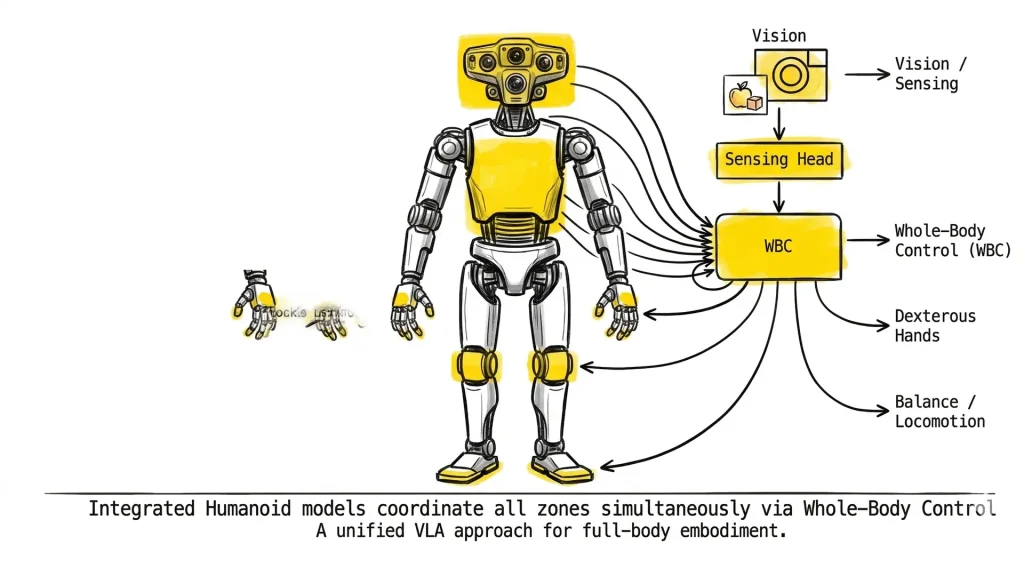
Fig. 06 – Annotated humanoid zones. Humanoid-Only models must coordinate Vision/Sensing, Whole-Body Control, Dexterous Hands, and Balance/Locomotion simultaneously – a fundamentally harder problem than single-task robot policies.
Humanoid-Only models typically incorporate specialized components: whole-body control (WBC) layers that coordinate upper and lower body simultaneously, hand and finger dexterity modules, and fall recovery or balance-aware planning architectures.
Some models are trained exclusively on humanoid teleoperation data – ensuring the training distribution precisely matches the deployment platform. Companies like Figure, Agility Robotics, 1X Technologies, and Unitree have all invested in proprietary models tailored to their specific hardware.
The tradeoff vs. Omni-Body approaches is real: specialization gains performance on target hardware but reduces portability. The field is actively debating whether the future belongs to specialized humanoid policies or to generalist systems that eventually reach humanoid-level performance.
On-Device Models: AI That Runs Inside the Robot
On-Device models run directly on the robot’s onboard compute – no cloud connection required. This is essential for real-world deployment where latency, connectivity, and data privacy make cloud inference impractical or impossible.
The gap between research and deployment often comes down to compute. A model that achieves state-of-the-art performance on a cluster of H100 GPUs is not useful inside a robot with a single edge GPU and a 10ms action loop. On-Device models are designed – from scratch or through optimization – to run within these constraints.
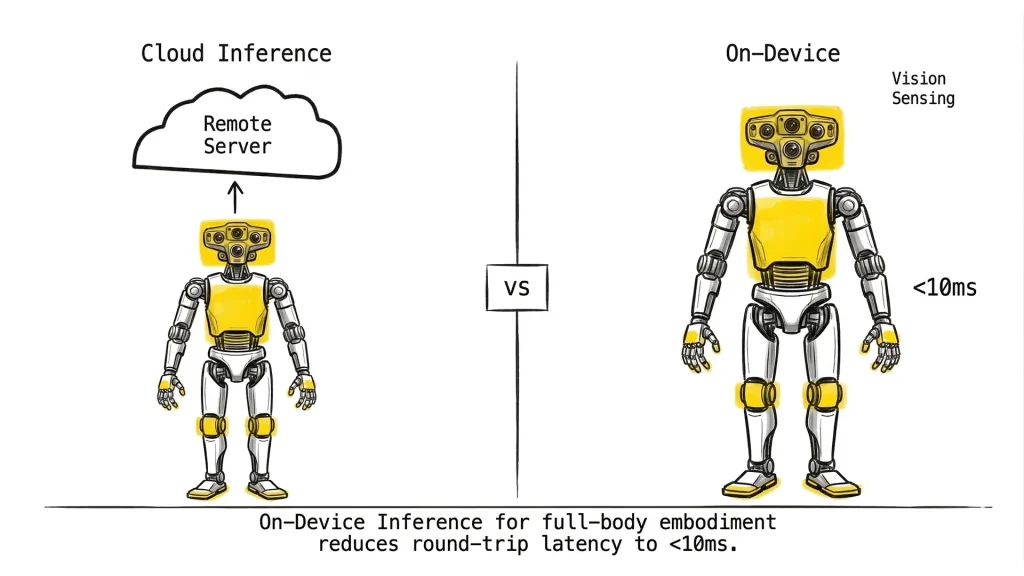
Fig. 07 – Cloud vs. On-Device inference. Cloud pipelines introduce round-trip latency that makes high-frequency control impossible. On-Device models run the entire inference loop inside the robot's compute stack – critical for dynamic balance and real-time manipulation.
Key techniques include model quantization (reducing precision from FP32 to INT8 or INT4), knowledge distillation (training a small “student” model to mimic a large “teacher”), and neural architecture search for efficiency. Target platforms include NVIDIA Jetson, Qualcomm’s robotics SoCs, and custom ASICs from robot OEMs.
On-Device deployment also matters for latency. High-frequency control loops (>50Hz) require sub-20ms inference. Cloud round-trips – even on low-latency connections – cannot meet this bar for dynamic tasks like bipedal balance recovery or dexterous in-hand manipulation.
The trend toward on-device AI is accelerating, driven by both hardware improvements (edge chips are getting dramatically faster) and software advances (smaller models are becoming increasingly capable as training and compression techniques mature).
Frequently Asked Questions
What is the difference between a VLA and a World Model?
A VLA (Vision-Language-Action) model maps perception and language directly to actions – it is a policy. A World Model is a predictive simulator of the environment – it predicts what happens next given an action. World Models are increasingly used as planners on top of which VLA policies execute.
Can a single model be both Omni-Body and Humanoid-Only?
Yes, to a degree. A model can be trained on diverse robot data (Omni-Body) and then fine-tuned on humanoid-specific data. The base model gains generalization; the fine-tuned version gains humanoid-specific performance. π0 from Physical Intelligence exemplifies this approach.
Why does On-Device matter if cloud AI keeps getting faster?
Physics is the bottleneck, not bandwidth. Even with 5G or dedicated low-latency links, round-trip network delays of 20–50ms are irreducible. A bipedal robot recovering from a stumble needs sub-10ms decisions – only possible with inference running locally on the robot’s compute.
What is the difference between Open Weights and Open Source?
Open Weights means the trained model parameters are publicly downloadable. Open Source means the developers also release the full training code, datasets, and methodology. A model can publish weights under a restrictive license without sharing anything about how it was trained.
How are Reward Models different from loss functions?
A loss function is a fixed mathematical objective that supervises training directly. A Reward Model is itself a trained neural network that learns to evaluate behavior from human preferences or demonstrations. It is adaptive and can generalize to new tasks – a loss function cannot.
Which foundation model type is most important for humanoid deployment?
This depends on the deployment context. For general manipulation tasks, VLA models are currently the most impactful. For safe real-world operation at scale, On-Device capability is non-negotiable. In practice, production humanoids combine all seven model types in a layered stack.