We just launched the first independent benchmark and rating system for humanoid robot foundation models
Free interactive platform evaluates 40 AI models across 10 capability dimensions, giving the robotics industry its first standardized way to compare the brains powering humanoid robots
STAVANGER, Norway, April 14, 2026
– Today, we launched the Humanoid Foundation Model Benchmark – a free, publicly accessible rating and comparison system that evaluates the 40 most significant AI foundation models designed to control humanoid robots. The benchmark is available immediately at humanoid.guide/foundation-models/.
As the humanoid robotics market accelerates toward commercial deployment, the question of which AI model should power a given robot has become one of the industry’s most consequential and least transparent decisions. Investors allocating capital, manufacturers selecting a software stack, and researchers benchmarking progress have until now lacked a single resource that maps the landscape in a structured, comparable way.
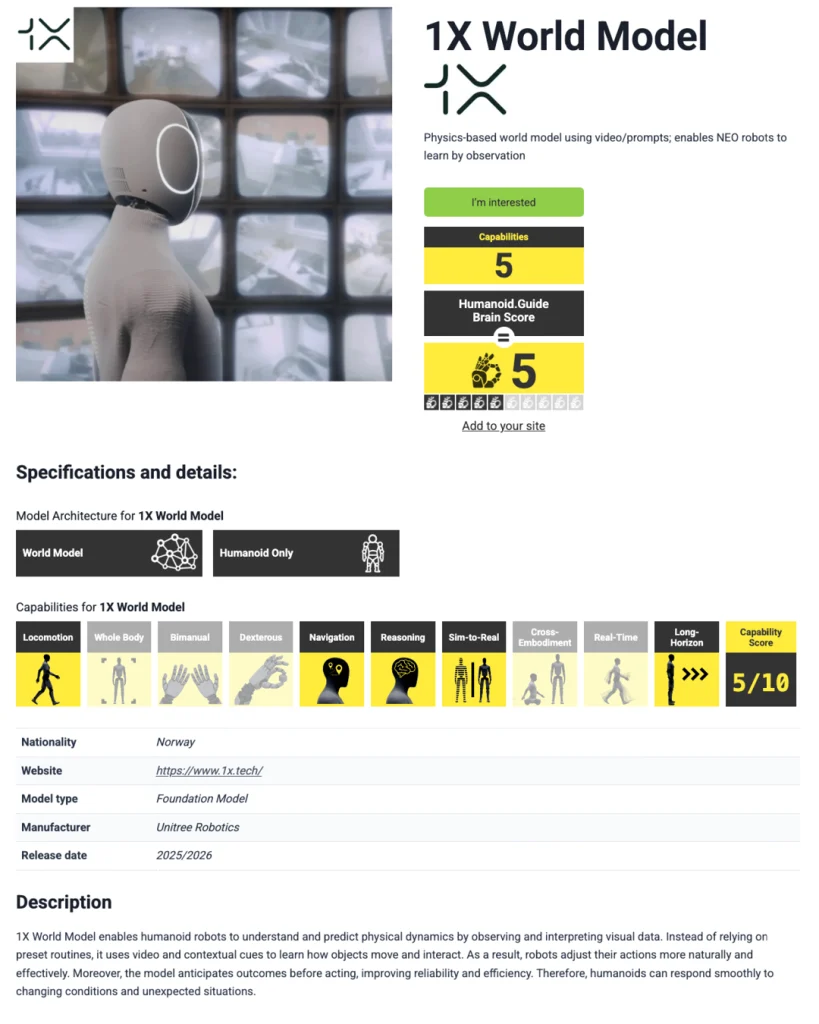
The Humanoid Foundation Model Benchmark addresses this gap. Each of the 40 models is evaluated and rated on a five-point scale, categorized by model type (Vision-Language-Action, World Model, or Reward Model), and assessed across 10 capability dimensions: locomotion, whole-body control, bimanual manipulation, dexterous manipulation, navigation, reasoning, sim-to-real transfer, cross-embodiment generalization, real-time inference, and long-horizon task planning.
Our interactive interface allows users to filter models by type, by whether they offer open weights, whether they target humanoid-only or omni-body applications, and whether they support on-device inference. Individual model profiles present specifications, test observations, and a capability breakdown.

Key facts
We have benchmarked 40 foundation models from leading organizations including NVIDIA, Google DeepMind, Tesla, Physical Intelligence, AgiBot, Skild AI, Figure AI, Meta AI, Sanctuary AI, Agility Robotics, 1X Technologies, Unitree, and BeingBeyond.
Three model categories are covered: Vision-Language-Action (VLA) models, World Models, and Reward Models.
10 standardized capability dimensions enable cross-model comparison on criteria that matter for real-world humanoid deployment.
The benchmark is free and openly accessible at humanoid.guide/foundation-models/ with no registration required.
Model developers can submit their own models for evaluation via the platform.
Why we built this
“The humanoid industry is producing remarkable foundation models at an increasing pace, but there has been no standardized, independent way to compare them,” said Christian Rokseth, founder of Humanoid.guide. “If you’re a manufacturer choosing between a VLA and a world-model approach, or an investor trying to understand which teams are actually solving dexterous manipulation versus locomotion, you need more than a press release – you need structured, comparable data. That’s what this benchmark delivers.”
Why this matters now
Foundation models are rapidly emerging as the critical differentiator in humanoid robotics. Unlike traditional robotics software stacks that require task-specific programming, foundation models promise general-purpose control — enabling a robot to understand natural language commands, perceive its environment, and generate coordinated whole-body movement from a single AI system. The choice of foundation model increasingly determines a humanoid robot’s capability ceiling.
The field remains fragmented. Models vary enormously in what they can actually do: some excel at bimanual manipulation but lack locomotion; others demonstrate strong sim-to-real transfer but have not been validated on dexterous tasks. Our benchmark provides the structured framework the industry needs to navigate these differences.
How we score
Our ratings are derived from a combination of published specifications, disclosed test data, peer-reviewed research, observed demonstrations, and general market feedback. Each model receives both an overall maturity rating and individual capability assessments. The evaluation framework is designed to evolve as the field matures, with new capability dimensions and models added on a rolling basis. Model developers are invited to submit their own models for inclusion.